Islam Mohamed
Connecting the Dots: A Knowledgeable Path Generator for Commonsense Question Answering

Paper contribution
- It is proposed to learn a multi-hop knowledge path generator dynamically to generate structured evidence based on the problem.
- The generator is based on a pre-trained language model, and uses a large amount of unstructured knowledge stored in the language model to supplement the incompleteness of the knowledge base.
- These related paths generated by the path generator are further aggregated into knowledge embeddings and merged with the context embeddings given by the text encoder.
Paper structure
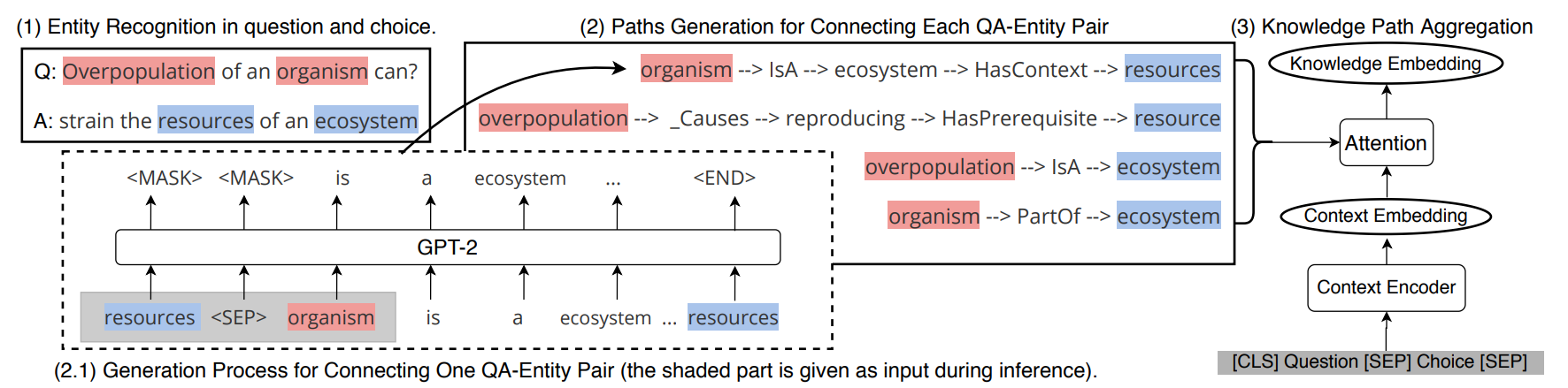
- Extract entities from question and answer choices.
- Use the constructed path generator to generate a multi-hop knowledge path to connect each pair of question answering entities.
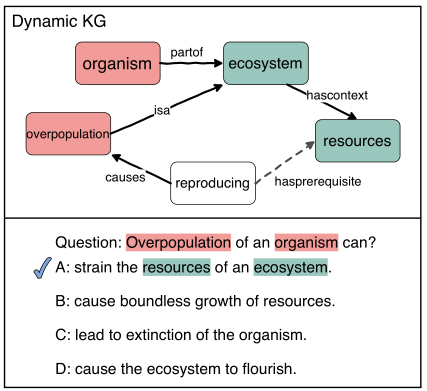
- The generator learns to connect the problem entity (red) and the choice entity (green) with the generated paths, which act as dynamic KGs for QA
- The generated paths are aggregated into a knowledge embedding and merged with the context embedding in the text encoder for classification.
Identify entities
- Identify the entity that appears in the question and the entity that appears in the option from the question option pair
- String matching (the method actually used in the paper)
- NER (Named Entity Recognition)
Knowledge path sampling
- Use random walks to extract symbolic paths from a commonsense KG, and sample representative relational paths for the GPT-2 knowledge path generator as the original training data.
Improve path quality
Assuming that these sample paths sampled by Random Walk contain knowledge related to commonsense question and answer tasks, in order to ensure the quality of these sampling paths, two heuristic strategies have been developed:
- Relevance: We filter out a subset of relational types that we assume to be unhelpful for answering commonsense questions, e.g., RelatedTo, prior to sampling.
- Informativeness: We require all relations types in a path to be distinct so it would not be trivial.
Local sampling (To help the generator to generate a path suitable for the task)
- E Is the entity set, R Is the relation set, E is composed of question entity and option entity, R Is the defined relationship collection relationship. In this way, a static knowledge graph (KG) is given,G=(E, R ).
- The random walk starts from the entities that appear in the question and answer choices in the task training set. The random walk algorithm performs path sampling on graph G, and the path form of sampling is (e0, r0, e1, r1,⋯,rT− 1,e T)Where eT ϵ E , rT ϵ R , T Hop count
Global sampling (To prevent the generator from biasing the path to generate the local structure of KG)
- Randomly sample some entities from the static KG, and start a random walk from them to get some paths other than the local KG for the generalization of the generator.
- In addition, a reverse relationship is added to each relationship, so that there are not only forward paths and reverse paths in the sampled path, which will make the path generator more flexible to connect the two entities.
- In addition, the paths with mixed hop counts are also sampled to train the generator to use variable-length paths to connect entities when needed. The paths with hop counts from 1 to 3 are sampled to construct a path set with mixed hop counts.
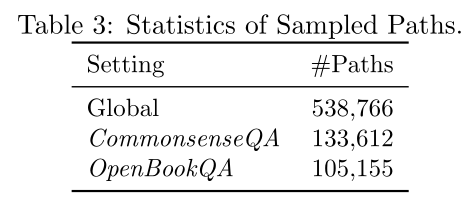
- The number of paths obtained from global sampling and local sampling of a specific task data set is shown in the following table.
- Combine the paths of these two sampling strategies and further divide them into training/development/test sets.
Building a path generator based on GPT-2
- Fine-tune GPT-2 on those paths sampled by random walks.
- GPT-2 is a pre-trained large-capacity language model, which encodes a wealth of unstructured knowledge from a huge corpus.
- The benefits of using it as a path generator are twofold.
- The structured knowledge path used in fine-tuning helps enrich GPT-2, enabling it to learn the ability to generate a “common sense” style path according to the design.
- The unstructured knowledge encoded by GPT-2 from the huge corpus can alleviate the sparsity problem of KG.
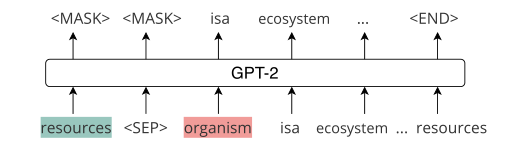
The sampled path is converted into textual input
- GPT-2 uses Byte Pair Encoding to create tokens in the vocabulary, which means that tokens are usually only part of a word.
- Use the Byte-Pair Encoding method of GPT2 to convert the symbol path obtained by directly sampling the random walk of the knowledge graph in the previous step into the text form of GPT-2 input: x = {X0, Y0, X1, Y1, … , YT−1 ,XT}
- Among them , Xt= {x0t, x1t , … , x len(et) t} Is an entity et The phrase token,
- And Yt= {y0t, y1t, … ,y len(rt) t} Is the relationship rt The phrase token.
- The path in the form of text generated in this way can be used as input in GPT-2.
GPT-2 generator input structure
- In order to further simulate the generator to provide a question entity and a scenario for selecting the entity, add the last entity phrase tag at the beginning of each path xT And a separate mark [SEP]. In this way, the generator will know the last entity it should output when generating the path.

- Pass the target entity + [SEP] mark + starting entity, that is, the gray part to the GPT-2 generator to generate a path connecting these two entities.
- The PG (path generation) learns to maximize the probability of the observed paths given the entity pairs. We use negative conditional log likelihood as a loss function:
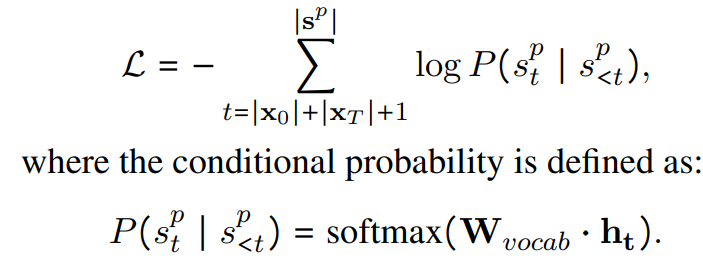
- Here ht denotes the final GPT-2 representation for s of T power p . Wvocab is the embedding matrix for the token based vocabulary used by GPT-2, which generalizes well to unseen words.
- During the inference, the target entity (e^a), the [SEP] token, and the starting entity (e^q ) are fed to our generator (the shaded part in previous Table), and greedy decoding is used to generate a path connecting the two entities.
Selection and construction of text encoder
- The framework of this article’s common sense question and answer consists of two main parts.
- The first part is the aforementioned path generator.
- The second part is a context encoder, which encodes questions and choices to output a context embedding c As unstructured evidence.
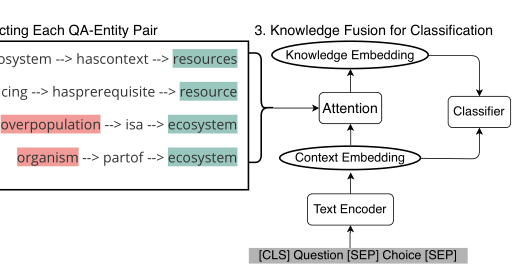
- The text encoder used in the experiment of this paper is BERT and Robert, two commonly used text input context encoders. Questions and choices are concatenated by adding some special tags, and then input into the context encoder to get c.
- Context embeddingc After paying attention to the path generated by the path generator, output a knowledge embedding p As structured evidence. Finally, the two types of evidence are input to the classifier, and a likelihood score is output for each choice.
KE (knowledge embedding) module
- We construct the path set P by generating a multi-hop path p(e^q, e^a) for each pair of a question entity e^q and a choice entity e^a with our PG and greedy decoding.
- To represent each path with an embedding, we perform mean pooling of the hidden states from the last layer of GPT-2 (before the softmax layer) as a new formulation for the function Pk:
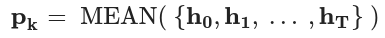
- Since not all paths will contribute equally to determining which choice is the correct answer, we use unstructured evidence, the contextual embedding c mentioned above, as a guide to encode this structured evidence.
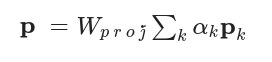
- where Wproj Is a learnable mapping matrix , αk The calculation formula of the attention weight embedded for each path is as follows
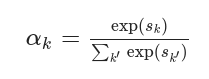
- Among them, sk The calculation formula of is as follows, the attention network is composed of W att And b att Parameterization
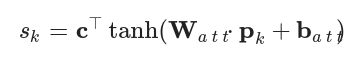
Fusion of heterogeneous information for classification
- The classifier uses the path embedding generated by the path generator p And contextual embedding of unstructured question options generated by the text encoder c To calculate the likelihood that the question is right.
- How to calculate the likelihood ?
- will c And p Connect them and provide them to the final linear classification layer to obtain a final score for each question option pair, which involves a linear transformation:
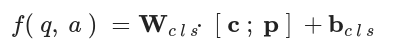
- Finally, the score is standardized through a softmax layer to obtain the final probability of all choices.
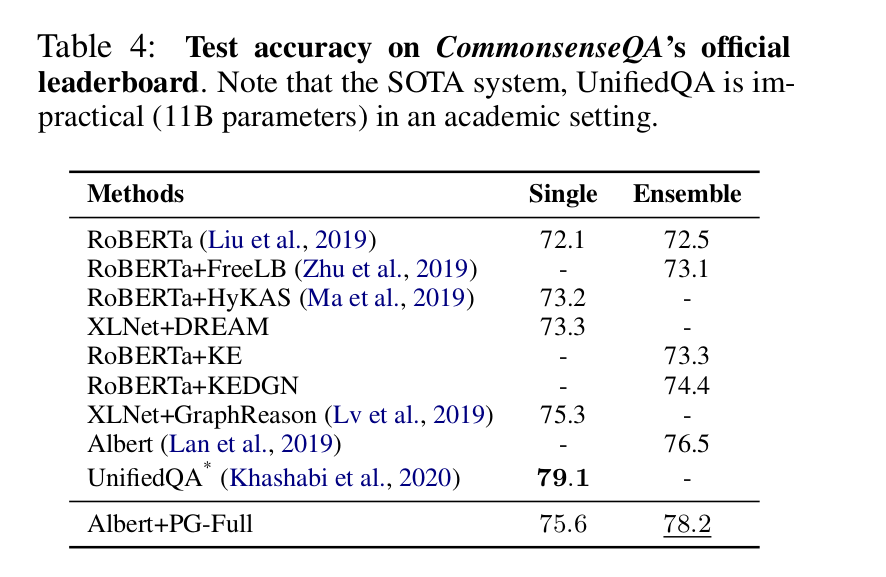
Results
- Results on csqa Dataset
Summary
- This paper proposes a generator for generating multi-hop knowledge paths as structured evidence to answer common sense questions.
- In order to learn such a path generator, GPT-2 was fine-tuned, and samples were randomly selected from a common sense KG. Then the generator connects each pair of question answering entities with a knowledge path.
- These paths are further aggregated into knowledge embeddings and merged with the context embeddings given by the text encoder.
- Experimental results on two benchmark data sets show that the framework of this paper is superior in performance to strong pre-training language models and static KG enhancement methods.
- In addition, it proves that the generated path can be explained in terms of information and help.
- Future work includes how to decouple the generator from the text encoder, and how to better integrate knowledge
Refrences
- https://www.cnblogs.com/caoyusang/p/13590705.html
- https://arxiv.org/pdf/2005.00691.pdf
Feel free to share!